
Or what do do if you run out of local datastore space and want to resize disks.
[warning: this is in lab environment. I wouldn’t do in production unless I was out of options]
Well shrinking disks is always bad, but the joys of SAN/iQ and network raid 10, means I should be able to pull apart the cluster. Completely rebuild the disks on the VSA and put the node back into the cluster and re-stripe from the other node(s). All whilst the storge is presented and being used.
So how did we end up wanting to do this anyway? Well with physical appliances I have had to recover from multiple disk failures, and predictive failures. In this instance I was trying out adaptive AO on SSD+SATA. I used all the SSD drive (120GB) for Tier0 and all the SATA (2TB) for capacity. The VSA OS was on a 3rd SATA drive. (FTR the hypervisor is on USB)
Yes I know the underlying volumes should be hardware raid protected for the VSA, but these servers only really have 2 disk slots. The SSD was attached to on board SATA. But on board SATA performance was sucking badly. so what I needed to do was to pull the SSD from where it was and lose the 250G drive.
I could have turned off the VSA, temp vmotioned the disks to a slower storage pool. rebuilt the local storage and then put everything back. But where is the fun in that? Anyway we need to know that this stuff really works.
So.
Step 1. Disable the Manager on the node we are taking out. Right Click, ‘Stop Manager…’
This may leave you with an error on the Management group, depending on how many nodes/managers you have.
Now if you try and repair storage system now, you will get:
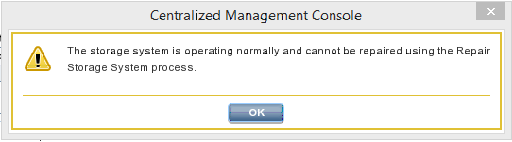
We need to ‘break it’. Log on to CLIQ (ssh port 16022 on the node) and run
utility run=”servicectl dbd_store stop”
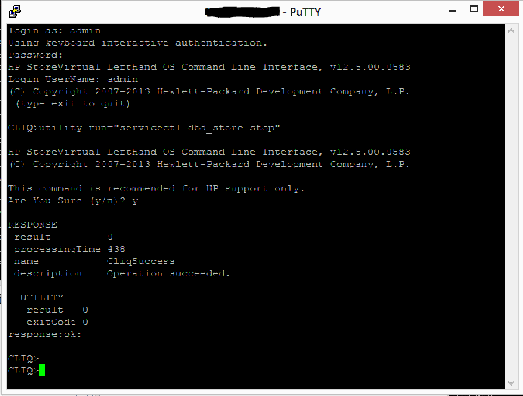
[Ref: http://h20564.www2.hpe.com/hpsc/doc/public/display?docId=mmr_kc-0112618]
CMC will now show that storage system is offline 🙂
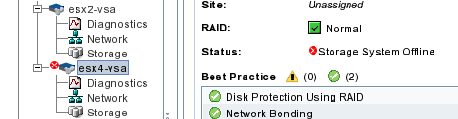
So now we can repair the storage system.
Right click on node. Select ‘Repair Storage System…’
This leaves a ‘ghost’ placeholder in the management group with the IP address of the node you have just removed and moves the node we want to work on to ‘Available Systems’
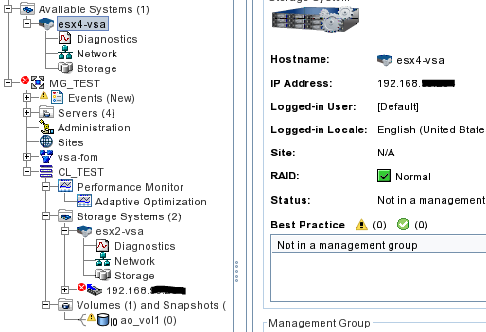
Yes I have blanked out RFC1918 IP addresses. No you can’t get to them.
You will see that the presented volume is still online, albeit in a degraded mode, and if you look in vSphere then the datastore is still fully functional.
Now we can mess with the drives, shrink them and generally smash the data.
What I did was, remove the capacity drive. Recreate one at 1.5TB and attach that is same place. (remeber to add back in SCSI controller 1, independent, persistent disk) I removed the SSD performance drive and Recreated at 100GB and attach it in same place. Then also moved the OS from the 250GB SATA onto the 2TB drive. The OS doesn’t need much in the way of performance.

So. After all that, the original OS disk remains, but the 2 data drives have been blown away and recreated,
Lets spin that VM up…..
Once booted, into CMC and ‘Find Systems’. Our node comes back online as an ‘Available System’ and, as expected, the Raid and Disks have errors.


On RAID Setup tasks, then reconfigure raid (Stripe is the only option in VSA)
And disks are all good

Don’t forget to set the Tier on the SSD back to Tier 0
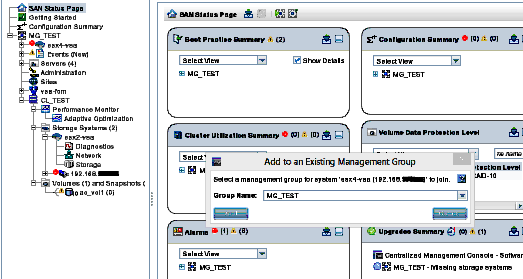
Now to replace the ‘ghost’ from earlier with the real VSA.
Add back to the original Management Group… Wait it takes a while…..
Right Click the CLUSTER (in this cas CL_TEST) and select Exchange Storage Systems.
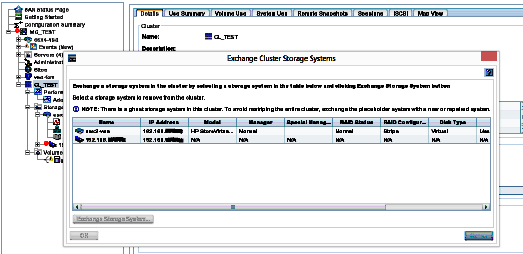
Select the ghost to replace, then the ‘repaired’ node.
This then swaps out the ghost with the actual system, then starts rebuilding the data volumes from the other node(s) in the cluster.
Volumes show as restriping, and when complete the ghost removes itself from the management group.
And don’t forget to restart a Manager on the node that you stopped earlier.
Last – but very important – step. Wait until the cluster has completely finished re-striping and all data volumes are back to normal, fully protected, status before messing with anything else in the cluster. NRaid10 can only protect you from so much…..